
Contexte :
Vearsa est une société de logiciels qui fournit des services de données à diverses industries en ligne. À l’origine un détaillant de livres électroniques, la marque a évolué pour tirer parti des données intelligentes pour aider les entreprises à vendre plus de produits en ligne. Vearsa, qui signifie « poésie » en gaélique, fait référence à la longue histoire de la narration irlandaise et perpétue la tradition d’aider les éditeurs à prospérer à l’ère numérique.
Besoin :
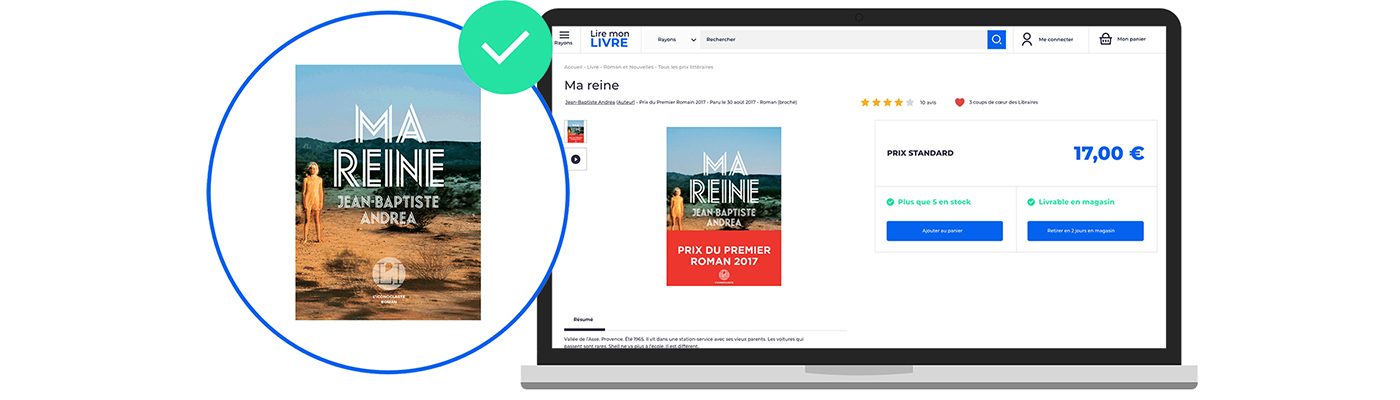
La plateforme de ebook Vearsa cherche à étendre la diffusion et les opportunités de ventes de livres électroniques sur des marketplaces en ligne. La société veut s’assurer que les images des livres mis en avant sur ces sites de distributeurs représentent bien les bonnes couvertures de livres (de la bonne maison d’édition, avec bon décor de couverture, et de la bonne année). Pour cela, Vearsa a besoin d’optimiser son processus de vérification et la ressource dédiée à régulièrement superviser et valider les couvertures en ligne, pour un volume de plus de 500 000 ebooks enregistrés dans sa base de données.
Objectifs :
- Augmenter ses ventes
- Optimiser son processus de conformité
- Assurer une bonne image de marque
Solution :
- Après avoir parcouru toutes les images de couvertures disponibles et leurs métadonnées associées, lancer l’algorithme de matching sur toutes les images de couvertures afin d’identifier celles qui ne correspondent pas
- Fournir notre API facilement déployable afin d’exécuter la technologie au sein de l’écosystème de Vearsa
- Assurer une technologie de reconnaissance d’image performante, robuste et scalable pour que le client puisse analyser un grand volume d’images




